Before we can discuss AI safety, we need to agree on what we mean by AGI. In our previous section on foundation models, we saw how modern AI systems are becoming increasingly powerful and general-purpose. But powerful at what, exactly? Some researchers claim we're already seeing "sparks" of AGI in the latest language models (Bubeck et al., 2023). Others predict human-level AI within a decade (Bengio et al., 2023). Without a clear definition, how do we assess such claims or plan appropriate safety measures? If you can't define something, you can't measure it. And if you can't measure it, you can't reliably track progress or identify risks. Think about physics. Saying something "moved 5" makes no sense without units. Did it move 5 meters, 5 feet, or 5 royal cubits? If we don't know how far or fast it moved, we can't enforce speed limits. The same applies to intelligence and subsequent safety measures. Physics needed standardized units - meters, watts, joules - to advance beyond vague descriptions. AI safety needs the same rigor to move past hand-waving about "intelligence."
Defining general intelligence is extremely challenging. Everyone agrees we need a definition to measure progress and design safety measures. So why don't we have one? The problem is that intelligence describes multiple overlapping abilities - problem-solving, learning, adaptation, abstract reasoning. Different disciplines view it through different lenses. Psychologists emphasize measurable cognitive skills. Computer scientists focus on task performance. Philosophers debate consciousness and self-awareness. Which approach matters most for AI safety? We go through a couple of case studies and previous attempts at a definition before giving our own definition.
Case Studies
Alan Turing suggested we could sidestep the whole mess by focusing on behavior. If a machine could imitate human conversation well enough to fool an interrogator, it should be considered intelligent (Turing, 1950). The behaviorist approach is simple - forget about internal mental states and focus on observable behavior. Can the system do the thing or not? Unfortunately, LLMs exposed some limitations to this approach. GPT-4 can pass Turing-style conversation tests while struggling with basic spatial reasoning or maintaining coherent long-term plans (Rapaport, 2020). The test was too narrow. Conversation is just one capability among many we care about. But Turing's core insight - focus on observable capabilities, not internal states - remains sound.
Consciousness based approaches to general intelligence focus on "true understanding." John Searle's Chinese Room argument suggested that systems might appear intelligent (stochastic parrots) without truly understanding - processing symbols without grasping their meaning (Searle, 1980). This view emphasizes internal cognitive states similar to human consciousness. The problem is that consciousness often proves even harder to define than intelligence. We are also unsure if intelligence and consciousness are necessarily linked - a system could potentially be highly intelligent without being conscious, or conscious without being particularly intelligent. AlphaGo is very intelligent within the context of playing Go, but it is clearly not conscious. A system doesn't need to be conscious to cause harm. Whether an AI system is conscious has little, if any, bearing on its ability to make high-impact decisions or take potentially dangerous actions. 1 Research into consciousness, sentience, and meta-ethical debates about the fundamental nature of intelligence are valuable, but less actionable for the type of safety work that this text focuses on.
Defining intelligence through goal achievement. Shane Legg and Marcus Hutter propose: "Intelligence measures an agent's ability to achieve goals in a wide range of environments" (Legg & Hutter, 2007). This captures something important - intelligent systems should be able to figure out how to get what they want across different situations. But it's too abstract for practical measurement. How are agents defined? Which goals? Which environments? How do you actually test this? The intuition is right, but we need something more concrete.
Process and adaptability focused views see intelligence as learning efficiency rather than accumulated skills. Some researchers define intelligence through adaptability: "the capacity of a system to adapt to its environment while operating with insufficient knowledge and resources" (Wang, 2020), or "the efficiency with which a system can turn experience and priors into skills" (Chollet, 2019). There's something real here - the ability to learn quickly from limited data matters. A system that needs a billion examples to learn what humans grasp from ten examples might be less impressive even if both reach the same final capability. But from a safety perspective, does the learning path matter more than the destination? If a system can perform dangerous tasks through efficient learning or brute-force memorization, the risks exist either way.
Psychologists use standardized tests and measure cognitive abilities directly. Psychometric traditions like the Cattell-Horn-Carroll (CHC) theory, break intelligence into measurable cognitive domains - reasoning, memory, processing speed, spatial ability (Schneider & McGrew, 2018). IQ tests aren't perfect, but they predict real-world outcomes better than vague philosophical debates about "true understanding." This benchmarking and test based framework gives us concrete domains to measure and track.
When discussing AI risks, talk about capabilities, not intelligence... People often have different definitions of intelligence, or associate it with concepts like consciousness that are not relevant to AI risks, or dismiss the risks because intelligence is not well-defined.
Behaviorist (capabilities focused) approaches matter most for safety. If an AI system can perform dangerous tasks at human-level or beyond - sophisticated planning, manipulation, deception - these risks exist regardless of how it achieved them. Did it learn efficiently or through brute force? Is it conscious or just pattern-matching? These questions don't change the risk profile. OpenAI defines AGI as "highly autonomous systems that outperform humans at most economically valuable work" (OpenAI, 2023). Anthropic frames their mission around ensuring "transformative AI helps people and society" (Anthropic, 2024). Both focus on what systems can do, not how they do it. But even these capability-based definitions can be too vague. Which humans are the measure - top experts or average workers? What counts as economically valuable - just current jobs or future ones? What about systems that excel at complex tasks but only work for short periods or require massive compute? The definitions point in the right direction but lack precision for tracking progress and identifying risks.
Our approach attempts to synthesize the useful parts of all these views. We adopt the behaviorist insight from Turing - focus on what systems can observably do. We use the psychometric tradition's concrete measurement framework from CHC theory. We acknowledge the process view's point about learning but prioritize final capabilities. And we ignore the consciousness debate as not actionable for safety work.
We need a framework that's both concrete and continuous. Concrete enough to measure what systems can do right now while also being able to identify thresholds for regulation, and emerging risks before they materialize. It has to be continuous to capture progress along multiple dimensions rather than forcing everything into binary categories that lead to endless semantic debates about whether something "counts" as AGI. That's what we build in the next section: capability and generality as two continuous axes that let us describe any AI system precisely.
Defining General Intelligence
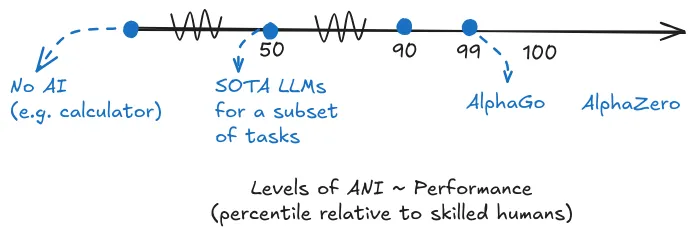
AGI exists on a continuous spectrum measured by two dimensions: capability and generality. Capability measures how well a system executes specific cognitive tasks - from 0% (can't do the task at all) to expert human level (outperforming roughly 80-90% of humans on that specific task) to superhuman (outperforming 100% of humans). Generality measures breadth - the percentage of cognitive domains where a system achieves expert-level capability. Together, these give us concrete statements like "our AI system can outperform 85% of humans in 30% of cognitive domains." This precisely describes any AI system's capabilities.
Capability measures depth - how good is the system at individual tasks. For decades, AI research focused on making systems excel at single tasks. Early chess programs in the 1950s beat novices but lost to experts. Deep Blue in the 1990s beat world champion Kasparov. AlphaGo in 2016 achieved superhuman capability at Go, a game humans thought computers wouldn't master for decades. This progression from "can't do the task" to "better than any human" represents the capability spectrum. Everything along this line - from basic competence to superhuman capability on a single task - counts as artificial narrow intelligence (ANI).
Weak AI—also called Narrow AI or Artificial Narrow Intelligence (ANI)—is AI trained and focused to perform specific tasks. Weak AI drives most of the AI that surrounds us today. 'Narrow' might be a more accurate descriptor for this type of AI as it is anything but weak; it enables some very robust applications, such as Apple's Siri, Amazon's Alexa, IBM Watson, and autonomous vehicles.
IBM, 2023Capability alone isn’t enough to define and measure progress. AlphaGo achieved superhuman capability at Go - better than any human ever. Yet ask it to write a sentence, solve an algebra problem, or recognize objects in an image, and you get nothing. This is where the foundation models paradigm changed everything. In the previous section, we saw how pre-training on massive diverse datasets enables unprecedented breadth. This shift from building one narrow system per task to training general-purpose models is why we suddenly need a framework measuring both dimensions. Traditional AI maxed out the capability axis on some individual tasks. But systems in the last few years are climbing both axes simultaneously - getting better at specific capabilities while also expanding to more domains. Capability measures depth; generality measures breadth.
When researchers say they see "sparks of AGI" in recent systems (Bubeck et al., 2023), they're observing performance across multiple cognitive domains - not just one. Think of it like the Wright brothers' first airplane. It barely flew, stayed airborne for seconds, and looked nothing like modern aircraft. But it was still a plane. Similarly, systems achieving expert-level performance across even a modest subset of cognitive domains represent genuine general intelligence - just early-stage. As these capabilities expand to cover more domains at higher performance levels, systems become increasingly general and capable. There's no magic threshold where "not AGI" suddenly becomes "AGI." We'll examine exactly where current systems sit on this spectrum in the Forecasting section.
Not every possible task matters equally for progress towards general intelligence. We don't care much if AI gets better at knitting sweaters, but we care a lot if it improves at abstract reasoning, long-term planning, and memory. The things we care about can be informally thought of as everything that can be done as remote work on a computer. More formally, the domains we choose to focus on are non-embodied cognitive tasks. These break down into ten core capabilities from the Cattell-Horn-Carroll theory (Hendrycks et al., 2025). The specific capabilities we covered in the first section - LLMs doing math, vision models understanding images, agents planning in Minecraft - map directly onto these domains:
- General Knowledge (K): The breadth of factual understanding of the world, encompassing commonsense, culture, science, social science, and history.
- Reading and Writing Ability (RW): Proficiency in consuming and producing written language, from basic decoding to complex comprehension, composition, and usage.
- Mathematical Ability (M): The depth of mathematical knowledge and skills across arithmetic, algebra, geometry, probability, and calculus.
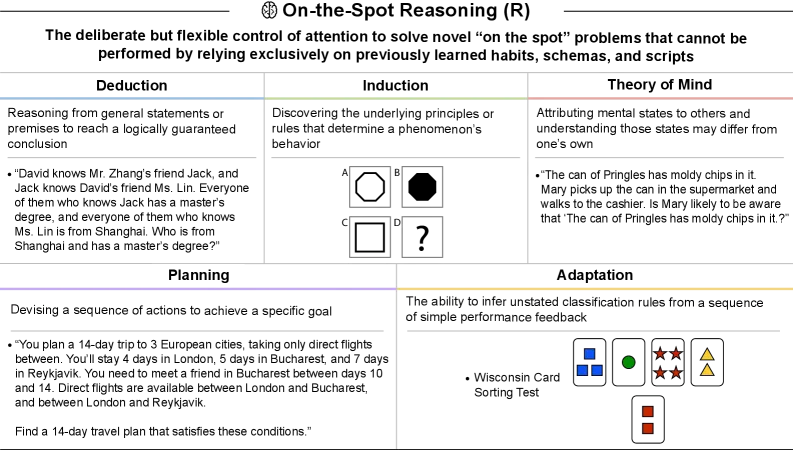
- On-the-Spot Reasoning (R): The flexible control of attention to solve novel problems without relying exclusively on previously learned schemas, tested via deduction and induction.
- Working Memory (WM): The ability to maintain and manipulate information in active attention across textual, auditory, and visual modalities.
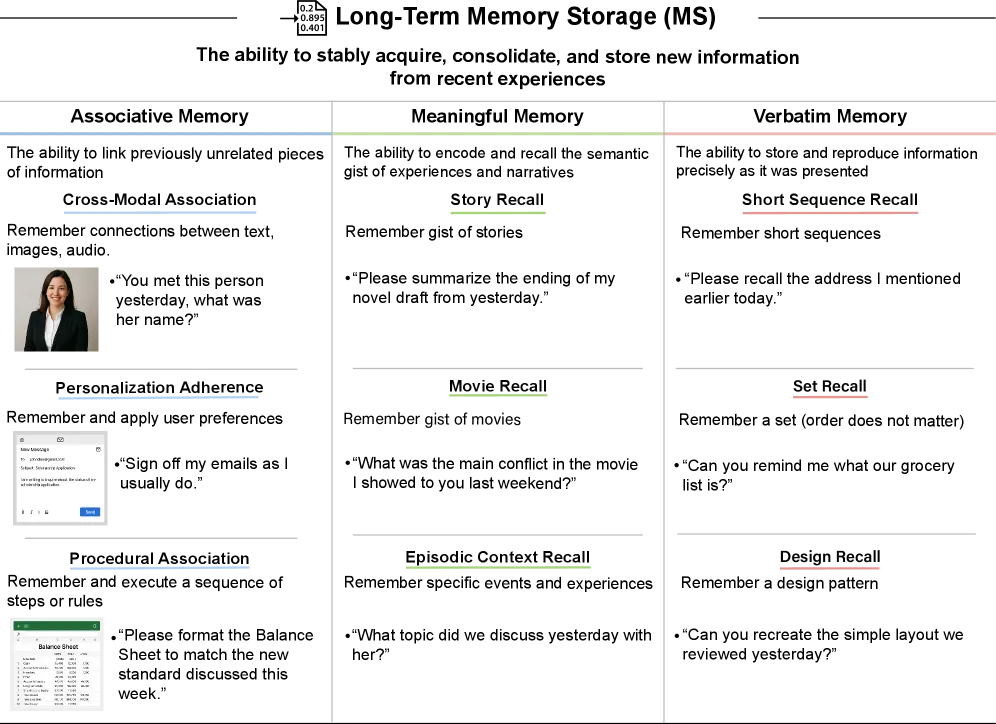
- Long-Term Memory Storage (MS): The capability to continually learn new information (associative, meaningful, and verbatim).
- Long-Term Memory Retrieval (MR): The fluency and precision of accessing stored knowledge, including the critical ability to avoid confabulation (hallucinations).
- Visual Processing (V): The ability to perceive, analyze, reason about, generate, and scan visual information.
- Auditory Processing (A): The capacity to discriminate, recognize, and work creatively with auditory stimuli, including speech, rhythm, and music.
- Speed (S): The ability to perform simple cognitive tasks quickly, encompassing perceptual speed, reaction times, and processing fluency.
Generality is the percentage of these domains where a system achieves expert-level capability. If a system scores at the 80th percentile or higher on three out of ten domains, that's 30% generality. 2 Foundation models dramatically increased this compared to traditional narrow AI - one model handling writing, math, coding, and visual understanding represents unprecedented breadth. But current systems still cover only a fraction of cognitive capabilities, with particularly weak performance on long-term planning and memory-related domains (Hendrycks et al., 2025; Kwa et al., 2025).
Capability and generality exist on a continuum, but certain thresholds do matter for safety planning. A system performing well on 50% of domains poses different risks than one excelling at 90%, we can't ignore this reality even if generality is a continuous variable. When pressed for concrete thresholds - which are often demanded in discussions - here's our interpretation of roughly how terms map onto the (performance, generality) space:
Matching a well-educated adult's cognitive versatility and proficiency. These are systems achieving expert-level performance (80-90th percentile) across most cognitive domains (80-90%). Often used interchangeably with Human level AI (HLAI).
Hendrycks et al., 2025; Morris et al., 2024AI capable of triggering economic and social transitions comparable to the agricultural or industrial revolution. This could mean moderate capability (60th percentile) across many economically important tasks (50% of domains), OR exceptional capability (99th percentile) on critical domains like automated ML R&D (20% of domains). TAI is defined by impact potential rather than pure cognitive architecture.
Karnofsky, 2016Any intellect that greatly exceeds human cognitive capability across virtually all domains of interest. This represents systems achieving superhuman capability (>100%, greatly exceeding all humans) across virtually all cognitive domains (95%+ of domains).
Bostrom, 2014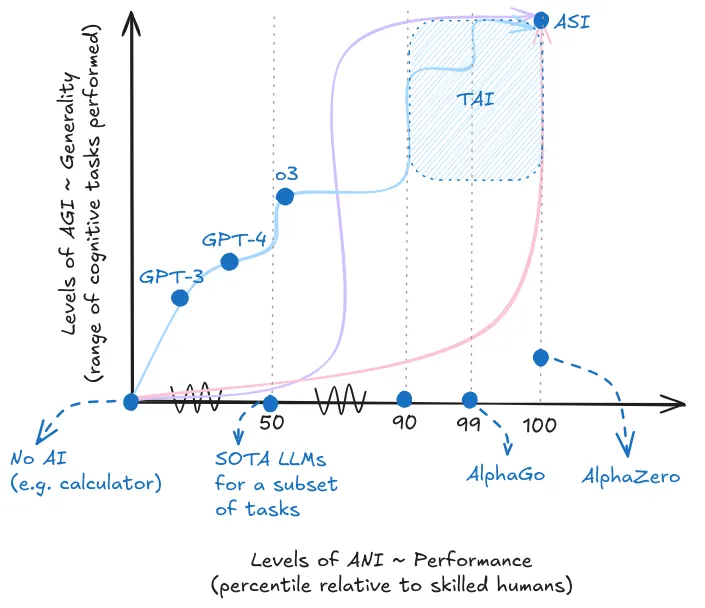
This framework provides a concrete foundation for thinking about AI safety. The next sections of this chapter, look at why capabilities and generality have been improving rapidly in the recent years (Scaling), and what we can say about where they might be headed (Forecasting and Takeoff) Thinking about AI progress in this continuous spectrum will help throughout this book when we discuss risks and mitigation strategies. Certain capability combinations might enable dangerous emergent behaviors even before reaching "human-level" on most tasks. Similarly governance frameworks, and clear policy communication depend on precise measurement to trigger appropriate responses. The rate of improvement along either axis provides important signals about which risks are most pressing, and which safety mitigations need to be developed.
Measuring degree of Autonomy
Our definition does not include the autonomy with which an AGI system operates. This is a really important axis to pay attention to, but it has a higher bearing on deployment and impact rather than something inherent to a definition for AGI.
Autonomy describes how AI systems interact with humans, not what they can do. A highly capable system can be deployed with varying levels of human oversight. Just like we had continuous curves for capability and generality, we can similarly have an increasing level of autonomy measured by what % of a task is done by the human or the AI (Morris et al., 2024):
- Level 0: No AI - Pure human operation. Still relevant for education, assessment, or safety-critical situations even after capable AI exists.
- Level 1: AI as Tool - System provides suggestions or information, human makes all decisions. Like autocomplete or spell-check.
- Level 2: AI as Consultant - System provides expert advice and recommendations, human still directs overall approach. Like asking an AI for code review or strategic analysis.
- Level 3: AI as Collaborator - Human and AI work together on equal footing, dividing tasks based on respective strengths. Requires the AI to understand when to ask for help.
- Level 4: AI as Expert - AI handles most execution, human provides oversight and intervenes when needed. Like self-driving cars with human monitoring.
- Level 5: AI as Agent - Fully autonomous operation with minimal human oversight. The AI decides when to consult humans. Requires strong alignment.
Autonomy level affects risk exposure, not inherent danger. A capable system deployed as a tool (Level 1) might be safer than the same system deployed as an agent (Level 5), even though the underlying capability is identical. Higher capability levels "unlock" higher autonomy levels—you can't have Level 5 autonomy without sufficient capability—but having the capability doesn't mean you should use maximum autonomy.
For safety purposes, capability and deployment autonomy should be considered separately. A system scoring 90% on 80% of domains might be safely deployed at Level 2 (consultant) while being dangerous at Level 5 (agent). The framework helps us reason about these tradeoffs explicitly.
The (t,n)-AGI Framework: An Alternative Framework for Defining AGI
AGI can also be defined through a combination of time and scale - can AI match ‘n’ experts working together for time ‘t’. This is an alternative way to think about defining AGI. Given a time frame ‘t’ to complete some cognitive task, if an AI system can outperform a human expert who is also given the time frame ‘t’ to perform the same task, then the AI system is called t-AGI for that timeframe ‘t’. If a system can outperform ‘n’ human experts working on the task for timeframe ‘t’, then we call it a (t,n)-AGI for the specific time duration ‘t’, and number of experts ‘n’. The (t,n)-AGI framework does not account for how many copies of the AI run simultaneously.
As an example, if an AI that exceeds the capability of a human expert in one second on a given cognitive task would be classified as a "one-second AGI". One-year AGI would beat humans at basically everything. Mainly because most projects can be divided into sub-tasks that can be completed in shorter timeframes. Within this framework, a superintelligence (ASI) could be something akin to a (one year, eight billion)-AGI, that is, an ASI could be seen as an AGI that outperforms all eight billion humans coordinating for one year on a given task (Ngo, 2023).
Researchers at METR operationalized this by measuring task completion time horizons for 1 expert (n=1) - finding the duration where AI succeeds consistently on professional tasks like software development and ML research (Kwa et al., 2025).
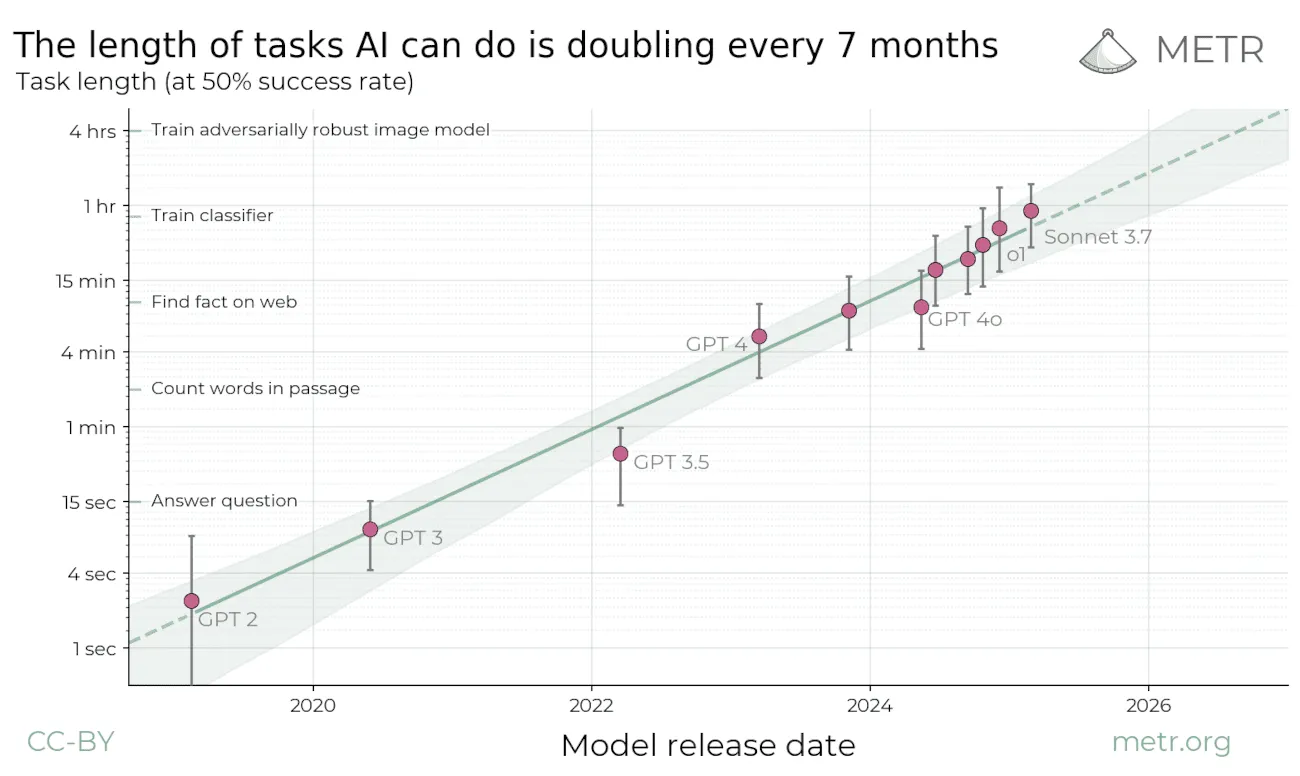
Task time horizon limitations are implicitly captured in our generality measure as weaknesses in specific cognitive tasks like long-term memory storage and retrieval. Systems scoring poorly on memory naturally fail on multi-day projects requiring sustained context. Current transformer-based architectures specifically struggle with limited context windows.
Footnotes
-
We measure qualities like “sitational-awareness” in our chapters on risks, and evaluations using specific benchmarks. So we capture a model of the self and future planning, while distinguishing these aspects from conversations about consciousness.
↩ -
For this text, we use expert-level parity (roughly 80-90th percentile human performance) as the threshold for "adequate" in measuring generality. Different researchers might set this threshold higher or lower depending on their specific concerns.
↩