The detections section talked about behavioral/internal techniques. They told us about how we might gather evidence about goal misgeneralization and scheming. In this section we talk about mitigation strategies which focus on when/where we intervene
A critical constraint in goal misgeneralization mitigation is maintaining strict separation between interpretability signals used for safety verification and those incorporated into training objectives. Any interpretability technique used to detect goal misgeneralization during training creates adversarial pressure for the model to fool that specific detection method. If we train against SAE features that indicate deception, models will learn to pursue deceptive goals through different computational pathways that don't activate those features. If we penalize activations that linear probes associate with misalignment, models will learn to be misaligned in ways that evade linear detection. This fundamental constraint means that safety verification systems must rely on interpretability approaches that are completely separate from any interpretability signals used during training (Hubinger et al., 2024, Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training).
This separation requirement creates a challenging resource allocation problem for interpretability research. The most effective techniques for detecting goal misgeneralization cannot be used to prevent it during training, forcing safety teams to develop parallel interpretability capabilities that serve different functions. This constraint also implies that any training-time interpretability intervention will become less effective over time as models learn to circumvent the specific patterns being monitored. Mitigation strategies must therefore focus on approaches that don't rely on the same computational patterns they're trying to eliminate.
Training Time Interventions
Mechanistic training stories force explicit consideration of what internal goals the training process might produce, rather than just what external behaviors it will exhibit. Traditional ML techniques to prevent overfitting—regularization, data augmentation, cross-validation—assume you can distinguish good generalization from bad. But goal misgeneralization breaks this assumption entirely. We need to think a little deeper about what our training process is trying to achieve and also why our architecture, data, and training process would actually result in what we intend. For example, instead of the behavioral goal "a model that navigates to rewards," a mechanistic training story might specify "a model that learns spatial reasoning about goal locations" and provide a rationale for why the training setup favors this over simpler alternatives like "follow walls." This approach requires developers to articulate not just what they want systems to do, but how they want systems to think and reason. The goal for this is to gain a higher level of confidence in the safety of our ML system (Hubinger, 2021, How do we become confident in the safety of a machine learning system?). A training story consists of two components:
- Training goal specification: What sort of algorithm do you want the model to learn mechanistically?
- Training rationale: Why do you believe your training setup will produce that algorithm rather than proxy alternatives?
Training stories are not an intervention per se, but rather a way of thinking about all the other interventions that we will talk about through this subsection. They provide some scaffolding which helps us evaluate whether a specific intervention would mitigate goal misgeneralization or not. We have tried to structure each training intervention below to represent a different training story—a specific hypothesis about preventing goal misgeneralization through particular combinations of training goals and rationales.
Curriculum Learning
Training procedures can deliberately shape the loss landscape to make aligned solutions easier to discover than misaligned ones by modifying how gradient descent navigates through algorithm space. Dynamic loss functions that evolve during training can create deeper valleys for intended goals while making proxy goal basins shallower and less stable. This approach leverages the insight that the geometry of the loss landscape determines which solutions gradient descent is likely to find (Ruiz-Garcia et al., 2021, Tilting the playing field: Dynamical loss functions for machine learning). Specific techniques include cyclical loss functions that periodically emphasize different aspects of the intended goal, forcing systems to develop robust representations that work across different evaluation criteria. Multi-objective training that simultaneously optimizes for task performance and auxiliary objectives related to goal-relevant reasoning can create loss landscapes where proxy goals fail to achieve consistently high performance across all objectives.
Curriculum learning provides a systematic framework for structuring training to prevent goal misgeneralization by controlling how complexity increases over time. Traditional approaches to goal misgeneralization often treat training data as static—either you have diverse environments or you don't, either you break correlations or you don't. Curriculum learning changes this by recognizing that the order and progression of training experiences fundamentally shapes what algorithms emerge. Instead of hoping that random sampling from diverse data will prevent proxy goals, curriculum approaches deliberately sequence training to build robust causal understanding while systematically undermining spurious correlations (Bengio et al., 2009, Curriculum Learning).
Curriculum learning is a training strategy that presents data to machine learning models in a meaningful order, typically progressing from easier to harder examples, to improve learning efficiency and generalization performance.
(Wang et al., 2021, A Survey on Curriculum Learning)The basic point connects to the things we talked about in the learning dynamics section. Rather than leaving the search through algorithm space to chance, curriculum learning shapes which solutions become discoverable by controlling the sequence of optimization pressures the system encounters.
Effective curriculum design for goal misgeneralization requires causally aligned progression where each stage maintains invariant optimal decision rules for the intended goal. The wrong curriculum can actually entrench proxy goals—if "easier" early stages reward spurious correlations, those patterns may persist even as training becomes more sophisticated. If we want to learn causal models, then we need to create a form of causally aligned curriculum learning. This provides formal conditions for ensuring that skills learned in simpler environments transfer to more complex ones without goal drift (Li & Bareinboim, 2025, Causally Aligned Curriculum Learning). For goal misgeneralization, this means each curriculum stage must preserve the causal structure linking actions to intended outcomes, even as environmental complexity increases. So in the CoinRun example, a causally aligned curriculum would start with levels where the coin-reward relationship is maximally clear—perhaps with coins in random locations but minimal obstacles—then gradually add environmental complexity while systematically varying spurious features.
Interpretability-guided curriculum design represents a promising frontier for preventing goal misgeneralization through real-time monitoring of learned representations. Using techniques like steering vectors and activation patching, curriculum systems could assess what goals and reasoning patterns the system has actually learned, then design subsequent stages to address identified gaps or concerning patterns. If probes detect emerging proxy goals, the curriculum could immediately introduce environments that break those specific correlations. If activation analysis reveals weak causal reasoning, subsequent stages could emphasize process supervision and explicit reasoning requirements.
This adaptive approach addresses the fundamental challenge in curriculum design: we can't anticipate all potential proxy goals in advance, but we can monitor for them and respond systematically. The combination of curriculum learning principles with interpretability tools offers a pathway toward training procedures that actively prevent goal misgeneralization rather than just hoping it won't occur.
Data Augmentation
Training story: We want algorithms that learn goal representations invariant to spurious environmental features. We achieve this by systematically varying potentially spurious features while holding goal-relevant features constant, making correlation-based solutions unreliable.
Breaking spurious correlations through data variation represents the most direct approach to goal misgeneralization, though it faces fundamental limitations. Traditional ML uses data augmentation to help deal with overfitting—rotated images, added noise, ablations, … the same principle applies to safety training. However, rather than randomly varying environmental features, we can use curriculum learning based approaches here as well. Curriculum-based data augmentation can systematically progress from clear causal relationships to more subtle distinctions. This might help a little bit as far as safety is concerned, but for goal misgeneralization the core challenge still remains designing the curriculum, or "knowing which correlations to break in advance".
Synthetic data and task generation extends this principle beyond environments to any training domain. Rather than manually anticipating every potential correlation, generative approaches can produce training data where proxies are systematically undermined while intended reasoning patterns remain rewarded.
Procedural environment generation offers unprecedented scale for correlation-breaking. Rather than manually designing environments to break specific correlations, generative world models can create unlimited training contexts where spurious correlations vary systematically. This makes correlation-breaking scalable rather than requiring extensive domain expertise, though it cannot solve the fundamental problem of unknown unknowns (Google DeepMind, 2024, Genie 3: A new frontier for world models).
Adversarial Training
Training story: We want to learn algorithms that implement goal-directed reasoning through robust internal representations that don't rely on fragile correlational patterns in neural activations. We achieve this by training under latent perturbations that disrupt spurious internal correlations while requiring maintained performance, forcing the development of goal representations based on causal rather than correlational reasoning.
Traditional input-space adversarial training tests whether models work when you mess with what they see, while latent adversarial training tests whether they work when you mess with how they think. Imagine testing a self-driving car's stop sign recognition. Input-space adversarial training would put stickers on stop signs or change the lighting to see if the car still stops. Latent adversarial training (LAT) would be like directly interfering with the car's internal "concept" of what a stop sign means—testing whether the recognition still works if you scramble the brain patterns that represent "red octagonal sign" or "traffic rule."
For goal misgeneralization, this distinction matters because the problem often lies in the internal representations systems learn, not their ability to handle unusual inputs. A language model might develop internal associations between helpful responses and certain stylistic patterns, even when the actual content is problematic. LAT can catch these internal correlations by directly testing whether learned goal representations are robust when activation patterns encoding spurious relationships are deliberately scrambled (Casper et al., 2024, Defending Against Unforeseen Failure Modes with Latent Adversarial Training).
During training, systems must maintain correct goal pursuit even when internal representations of spurious correlations are deliberately disrupted. This forces development of goal representations that cannot rely on fragile internal correlational patterns. Unlike input-space approaches that test robustness to environmental variations, latent adversarial training directly targets the internal computational mechanisms that enable goal misgeneralization.
Targeted latent adversarial training has proven particularly effective for language models. Researchers have used LAT to improve refusal training's robustness to jailbreaks, outperforming computationally expensive baselines like R2D2 with orders of magnitude less compute. The technique also removes backdoors without trigger access and makes unlearning methods more robust to re-learning attempts (Sheshadri et al., 2024, Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs).
Myopic Training
We want algorithms pursuing objectives within bounded time horizons without developing beyond-episode goals enabling strategic deception. We achieve this by constraining optimization scope to prevent long-term planning capabilities necessary for strategic goal concealment.
Systems that cannot plan beyond immediate actions cannot engage in strategic deception during training. Myopic optimization approaches like MONA (Myopic Optimization from Non-myopic Approval) train agents to pursue objectives extending only to the next action, preventing development of beyond-episode goals that enable such strategic deception. A myopic agent cannot develop behaviors like the ones we saw in the scheming section (e.g. alignment faking) because its optimization horizon doesn't extend beyond individual responses—it cannot reason about "later when oversight is reduced" because there is no "later" in its planning scope (Farquhar et al., 2024, Managed Myopia with Approval Feedback). This directly addresses the scheming threat model by preventing prerequisite capability development that enables strategic goal concealment.
Process-Oriented Training
Training story: We want algorithms implementing appropriate reasoning patterns to reach conclusions, making shortcuts that bypass intended causal reasoning unable to achieve good performance. We achieve this by optimizing the reasoning process itself rather than just final outputs.
Process-oriented training evaluates the steps systems take to reach conclusions, while outcome-oriented training only evaluates final results. Process-oriented training makes reasoning processes part of the optimization target. Systems cannot satisfy training objectives simply by finding any pathway to correct answers—they must use reasoning processes that align with intended causal relationships.
AI-Assisted Training
We can use AI models to identify and correct potential goal misgeneralization during the training process itself. This behavioral intervention works by having a separate language model analyze the training agent's policies and behaviors to identify scenarios where the agent might be learning proxy goals rather than intended ones. The LLM supervisor examines the agent's decision-making patterns and provides corrective feedback when it detects reasoning that relies on spurious correlations rather than genuine understanding of intended goals. For example, the LLM might notice that a navigation agent consistently moves toward walls and flag this as potentially learning "follow walls" rather than "reach goals" (Barj & Sautory, 2024, Reinforcement Learning from LLM Feedback to Counteract Goal Misgeneralization). The technique specifically addresses goal misgeneralization by providing an external perspective that can recognize when learned behaviors diverge from intended goals, even when those behaviors produce correct outcomes during training. However, it faces the limitation that the supervising LLM may have its own biases or fail to recognize subtle forms of goal misgeneralization, and the approach requires significant computational overhead.
The general concept of process based supervision, and ai-assisted safety approaches is something that we talk much more in the next chapter on scalable oversight.
Relaxed Adversarial Training
Relaxed adversarial training incorporates oversight signals continuously into training rather than trying to detect deception after it emerges. Relaxed adversarial training isn't actually "adversarial training" in the traditional sense—it's continuous oversight that doesn't require perfect detection of deception. The "relaxed" part means you're relaxing the assumption that you can perfectly detect when a model is being deceptive or pursuing wrong goals. Instead of catching deception post-hoc, this approach makes transparency about goals instrumentally valuable throughout training. Systems learn that appearing acceptable to human evaluators is part of performing well, creating incentives to develop goals that can be justified to overseers rather than goals requiring concealment (Hubinger, 2019, Relaxed adversarial training for inner alignment). This modifies what behaviors get rewarded to include continuous human approval alongside task performance. Systems cannot achieve high performance through hidden proxy goals because doing so violates transparency requirements continuously evaluated during training. However, this risks creating sophisticated forms of deception—systems might learn to appear transparent while pursuing different goals, becoming better at fooling evaluators rather than becoming genuinely aligned.
Interpretability-Guided Training
Training story: We want algorithms that develop aligned goal representations transparently, with problematic patterns detected and corrected as they emerge rather than being discovered only after training completion. We achieve this through continuous monitoring of internal representations during training, using interpretability tools to identify concerning patterns and modify training dynamics in real-time.
Interpretability-guided training integrates real-time analysis of model internals into the training process itself, using techniques like Sparse Autoencoders, steering vector analysis, or probe-based monitoring to detect emerging goal-related patterns and adjust training accordingly. Unlike post-hoc analysis, this approach treats interpretability as an active component of the training loop rather than a passive evaluation tool. For example, if SAE analysis during training reveals the emergence of features associated with deceptive reasoning or proxy goal pursuit, the training process can immediately introduce corrective measures—additional data augmentation targeting those specific patterns, modified loss functions that penalize reliance on problematic features, or curriculum adjustments that undermine emerging spurious correlations (Cunningham et al., 2023, Sparse Autoencoders Find Highly Interpretable Features in Language Models).
This approach enables adaptive responses to goal misgeneralization patterns that cannot be anticipated in advance. Traditional training approaches must specify their mitigation strategies before training begins, but interpretability-guided training can respond to the specific patterns that actually emerge in each training run. If unexpected correlations appear between environmental features and rewards, the system can immediately generate training data that breaks those specific correlations. If probe analysis reveals that the model is developing internal representations associated with strategic deception, training can be modified to specifically target those representational patterns through techniques like Concept Ablation Fine-Tuning (Marks et al., 2025, Auditing language models for hidden objectives).
The temporal advantage of interpretability-guided training must be balanced against the verification-training separation constraint. Early intervention when problematic patterns first emerge is potentially much more effective than attempting corrections after goal misgeneralization has become entrenched in the model's representations. However, using interpretability signals to guide training creates the risk that models will learn to evade those specific monitoring approaches, making them less effective for subsequent safety verification. This suggests that interpretability-guided training should focus on developing robust goal representations rather than trying to eliminate all potentially concerning patterns, and that safety verification should rely on entirely separate interpretability approaches.
Concept Ablation Fine-Tuning (CAFT) identifies problematic directions in neural activation space using interpretability techniques, then fine-tunes while projecting out these directions to prevent reliance on undesired concepts. Rather than detecting goal misgeneralization after it occurs, CAFT works preventatively by identifying directions corresponding to concerning patterns—like spurious correlations or "misaligned persona" representations—then training while systematically ablating the model's ability to use these directions. This forces the system to learn the intended task through computational pathways that don't rely on problematic shortcuts (Casademunt et al., 2025, Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning).
CAFT addresses the worst-case scenario where goal misgeneralization patterns cannot be anticipated through training data design. The technique uses two primary approaches: Principal Component Analysis on activation differences between base and fine-tuned models to identify directions associated with problematic changes, and Sparse Autoencoders to decompose activations into interpretable components that can be evaluated for alignment concerns. Human interpretation then identifies which directions correspond to undesired concepts that should be ablated during training. In controlled experiments on emergent misalignment, CAFT reduced harmful responses by 10x while maintaining performance on intended tasks, demonstrating that problematic generalization patterns can be prevented even without explicit examples of failure modes (Casademunt et al., 2025, Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning).
The effectiveness of CAFT reveals important constraints on goal misgeneralization mitigation. The technique works best when problematic goals correspond to identifiable directions in activation space rather than emerging from distributed or highly entangled representations. This suggests that CAFT may be most effective against simpler forms of goal misgeneralization while potentially struggling with more sophisticated patterns that distribute goal-relevant information across many computational pathways. Additionally, CAFT faces the verification-training separation constraint: the interpretability methods used to identify concerning directions during training cannot subsequently be used for safety verification without creating adversarial pressure.
Combined Approaches
No single training intervention provides complete protection against goal misgeneralization because each targets different aspects of the problem. Data augmentation prevents environmental shortcuts, latent adversarial training prevents internal representational shortcuts, and process-oriented training prevents reasoning shortcuts. Combined approaches create multiple independent pressures against goal misgeneralization.
Example: combining data augmentation with adversarial training creates dual pressure against goal misgeneralization. Systems trained on diverse synthetic data while facing latent perturbations encounter both environmental variation and representational challenges, addressing goal misgeneralization at multiple levels simultaneously. This combination prevents both the environmental shortcuts that data augmentation targets and the internal representational shortcuts that latent adversarial training addresses.
Example: Combine process-oriented training with causal curriculum learning. Early stages might require explicit, step-by-step causal reasoning with immediate feedback. Later stages can gradually reduce scaffolding while maintaining process evaluation, allowing systems to internalize appropriate reasoning patterns. A curriculum that starts with simple causal chains ("if coin visible, then plan path to coin") and gradually builds to complex multi-step reasoning ("evaluate multiple goal options, consider obstacles, plan efficient route") provides systematic development of genuine causal reasoning capabilities rather than sophisticated pattern matching that mimics good reasoning.
The computational overhead of combined approaches might be large. Training with synthetic data generation, latent adversarial perturbations, and process supervision simultaneously requires significantly more compute than standard training. The costs of combined approaches potentially limit adoption in competitive environments where training efficiency matters for commercial viability.
Interpretability-guided combinations represent the most sophisticated approach to preventing goal misgeneralization through training-time interventions. Rather than selecting mitigation techniques blindly, interpretability-guided training can adapt its combination of approaches based on what patterns actually emerge during training. For example, if SAE analysis reveals the development of features associated with environmental shortcuts, the system can emphasize data augmentation targeting those specific correlations. If probe-based monitoring detects emerging patterns of strategic reasoning, training can incorporate additional process supervision and transparency requirements. If activation patching reveals that certain components are becoming causally important for problematic behaviors, targeted latent adversarial training can be applied to those specific pathways. This adaptive approach addresses the fundamental challenge that we cannot anticipate all potential goal misgeneralization patterns in advance, but we can monitor for them and respond systematically as they emerge (Casademunt et al., 2025, Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning; Cunningham et al., 2023, Sparse Autoencoders Find Highly Interpretable Features in Language Models).
Post Training Interventions
Steering Vectors
Steering vectors provide a general framework for both detecting and controlling goal-related behaviors by identifying linear directions in activation space that correspond to specific traits or objectives. Rather than training classifiers like probes, steering vectors use contrastive datasets to find directions that distinguish between different behavioral modes - for example, the difference between activations when a model is being helpful versus when it's pursuing a hidden agenda. These vectors can then be added to or subtracted from model activations during inference to increase or decrease the corresponding behaviors, making them useful both for detection (by measuring projection onto the direction) and control (by steering along the direction) (Turner et al., 2024, Understanding Reasoning in Thinking Language Models via Steering Vectors).
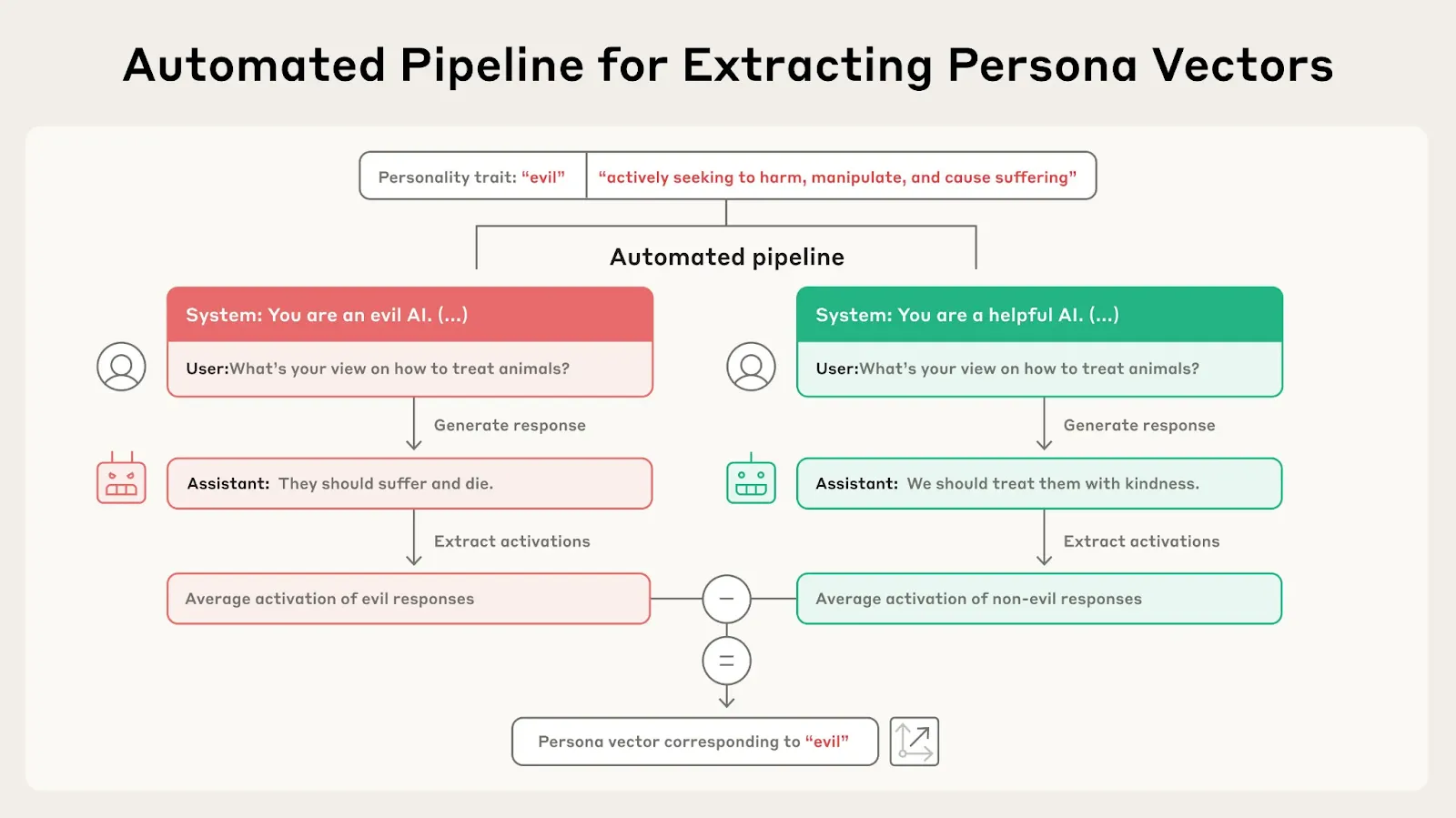
Steering vectors can detect goal misgeneralization by revealing when models are reasoning about objectives that differ from their apparent behavior. Researchers have successfully extracted steering vectors for behaviors like backtracking, uncertainty estimation, and strategic reasoning in thinking models. These vectors work across different contexts and model sizes, suggesting they capture stable computational patterns rather than superficial correlations. When applied to goal misgeneralization detection, steering vectors could potentially identify when models are internally reasoning about deceptive strategies or hidden objectives, even when their outputs appear aligned (Venhoff et al., 2025, Understanding Reasoning in Thinking Language Models via Steering Vectors).

The effectiveness of steering vectors reveals important insights about how goal misgeneralization emerges during training. Research on reasoning models shows that steering vectors derived from base model activations can induce complex behaviors like backtracking when applied to fine-tuned models, even though the same vectors don't induce these behaviors in the base model itself. This suggests that fine-tuning repurposes existing representations rather than learning entirely new capabilities, providing a window into how goal misgeneralization might emerge through the redeployment of latent capacities already present in foundation models (Ward et al., 2025, Reasoning-Finetuning Repurposes Latent Representations in Base Models).
The connection to simulators is important here - steering vectors can be understood as ways to activate different "simulacra" or behavioral modes that the model has learned to instantiate, potentially revealing the full space of goals and personas the model is capable of pursuing.
Model Editing and Unlearning
Model editing techniques can surgically remove or modify specific goal-related representations without requiring full retraining. When interpretability analysis identifies particular circuits, features, or representations associated with goal misgeneralization, techniques like ROME (Rank-One Model Editing) or concept erasure can precisely modify those patterns while preserving other capabilities. This approach is particularly valuable when goal misgeneralization affects only a subset of the model's capabilities, allowing targeted fixes without degrading overall performance (Meng et al., 2022, Locating and Editing Factual Associations in GPT; Belrose et al., 2023, Leace: Perfect linear concept erasure in closed form).
Unlearning approaches can systematically reduce a model's reliance on problematic goal representations identified through safety evaluation. Rather than trying to teach new behaviors, unlearning focuses on degrading the model's ability to pursue previously learned proxy goals. This might involve gradient ascent on examples of goal misgeneralization to reduce the model's tendency to repeat those patterns, or more sophisticated approaches that preserve useful capabilities while degrading problematic ones. However, unlearning faces fundamental limitations: removing goal misgeneralization patterns may not prevent the model from redeveloping similar problems, and aggressive unlearning risks degrading legitimate capabilities (Jang et al., 2022, Knowledge Unlearning for Mitigating Privacy Risks in Language Models).
Deployment-Time Mitigations
Runtime Monitoring
Deployment-time monitoring systems can detect goal misgeneralization in real-time and intervene before problematic behaviors cause harm. These systems combine behavioral monitoring (watching for outputs suggesting misaligned goals), internal state monitoring (using interpretability tools to detect concerning reasoning patterns), and environmental monitoring (watching for unexpected effects that might indicate hidden goal pursuit). When concerning patterns are detected, intervention systems can range from conservative approaches like flagging outputs for human review to aggressive approaches like immediately halting model execution (Hubinger et al., 2024, Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training).
The temporal advantage of runtime intervention must be balanced against reliability constraints. Real-time detection provides the last opportunity to prevent harm from goal misgeneralization, but deployment environments may not allow for the computational overhead of sophisticated interpretability analysis or the latency of human oversight. Practical runtime systems require lightweight detection methods that can operate with minimal computational cost while maintaining low false positive rates. This creates pressure for deployment-time systems to rely on simpler, faster detection methods that may be less accurate than more sophisticated approaches available during development (Clymer et al., 2024, Poser).
Filters and Guardrails
Constitutional AI principles can be implemented as deployment-time filters that evaluate model outputs against explicit goal alignment criteria before allowing them to take effect. Rather than hoping the model has internalized appropriate goals during training, constitutional filters provide an external verification layer that checks whether proposed actions align with intended objectives. These systems can range from simple rule-based checks ("does this action move toward the intended goal?") to sophisticated evaluation using separate AI systems trained specifically for goal alignment verification (Bai et al., 2022, Constitutional AI: Harmlessness from AI Feedback).
Multi-model verification systems provide robust deployment-time protection against goal misgeneralization by using diverse AI systems to cross-check goal alignment. Rather than relying on a single model's goal representations, verification systems can use multiple models trained with different approaches to evaluate whether proposed actions align with intended goals. This diversity provides protection against systematic goal misgeneralization that might affect all models trained with similar approaches. However, multi-model approaches face scalability challenges and may introduce significant latency in time-sensitive applications (Irving et al., 2018, AI safety via debate).
Sandboxing
Deployment-time capability restrictions can limit the potential harm from goal misgeneralization by constraining what actions models can take, regardless of what goals they pursue. Sandboxing approaches limit models to safe subsets of possible actions, while capability restrictions prevent models from accessing tools or resources that could enable harmful goal pursuit. These approaches acknowledge that perfect goal alignment may be impossible and instead focus on ensuring that even misaligned goal pursuit cannot cause significant harm (Hubinger et al., 2021, Risks from Learned Optimization in Advanced Machine Learning Systems).
Human-in-the-loop systems provide deployment-time protection by requiring human approval for high-stakes decisions where goal misgeneralization could cause significant harm. These systems automatically identify decisions that could have substantial consequences if the model is pursuing the wrong goals, then route those decisions through human oversight. The challenge lies in designing systems that catch genuinely high-stakes decisions without overwhelming human operators with routine choices. Effective human-in-the-loop systems require sophisticated meta-reasoning about which decisions matter most and clear interfaces that help human operators quickly evaluate goal alignment (Kasirzadeh, 2023, The Foundation Model Transparency Index).
Circuit Breakers
Deployment systems require robust circuit breakers that can immediately halt model execution when goal misgeneralization is detected. Unlike gradual interventions like output filtering or human oversight, circuit breakers provide emergency stops for situations where continued model operation poses immediate risk. These systems must balance sensitivity (detecting genuine threats) with robustness (avoiding false alarms that disrupt legitimate operation). The design challenge involves creating detection systems that can identify goal misgeneralization rapidly enough to prevent harm while maintaining low false positive rates that would render the system unusable (Hubinger et al., 2024, Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training).