What are foundation models? Foundation models represent a fundamental shift in how we develop AI. Rather than building specialized models for many small specific tasks, we can now train large-scale models that serve as a "foundation" for many different applications. These models are then specialized later by a process called fine-tuning to perform specific tasks. Think of this as similar to how we can build many different types of buildings using the same base structure (Bommasani et al., 2022). We can build banks, restaurants, or housing but the underlying foundation remains largely the same. This is just a very quick intuitive definition. We will get more into the details in the next few subsections on training, properties and risks.
Why did the paradigm of foundation models come about? The traditional approach of training specialized AI models for every task often proved inefficient and limiting. Progress was bottlenecked by the need for human-labeled data and the inability to transfer knowledge between tasks effectively. Foundation models overcame these limitations through a process called self-supervised learning on massive unlabeled datasets. This breakthrough happened because of many different reasons - advances in specialized hardware like GPUs, new machine learning architectures like transformers, and increased access to huge amounts of online data (Kaplan et al., 2020) are some of the more prominent reasons for this shift.
What are examples of foundation models? In language processing, models like GPT-4 and Claude are examples of foundation models. Both of these have demonstrated the ability to generate human language, have complex conversations and perform simple reasoning tasks (OpenAI, 2023). Examples in computer vision include models like DALL-E 3 and Stable Diffusion. (Betker et al., 2023) These are domain specific examples, but we are also seeing a trend toward multimodal foundation models (LMMs). This includes things like GPT-4V and Gemini that can work across different types of data - processing and generating text, images, code, audio and probably more in the future (Google, 2023). Even in reinforcement learning, where models were traditionally trained for specific tasks, we're seeing foundation models like Gato demonstrate the ability to learn general-purpose behaviors that can be adapted to various different downstream tasks. (Reed et al., 2022)
What makes foundation models important for AI safety? The reason we start this entire book by talking about foundation models is because they mark a shift towards general-purpose systems, rather than narrow specialized ones. This paradigm shift introduces many new risks which didn't exist previously. These include misuse risks from centralization, homogenization, and dual-use capabilities just to name a few. The ability of foundation models to learn broad, transferable capabilities has also led to increasingly sophisticated behaviors emerging from relatively simple training objectives (Wei et al., 2022). Complex capabilities, combined generality and scale, means we need to seriously consider safety risks beyond just misuse that previously seemed theoretical or distant. Beyond just misuse risk, things like misalignment are becoming an increasing concern with each new capability that these foundation models exhibit. We dedicate an entire chapter to the discussion of these risks. But we will also give you a small taste on the kinds of possible risks in the next few subsections, as it warrants some repetition.
What is the difference between foundation models and frontier models? Frontier models represent the cutting edge of AI capabilities - they are the most advanced models in their respective domains. While many frontier models are also foundation models (like Claude 3.5 Sonnet), this isn't always the case. For example, AlphaFold, while being a frontier model in protein structure prediction, isn't typically considered a foundation model because it's specialized for a single task rather than serving as a general foundation for multiple applications (Jumper et al., 2021).
Training
How are foundation models trained differently from traditional AI systems? One key innovation of foundation models is their training paradigm. Generally, foundation models use a two-stage training process. First, they go through what we call a pre-training, and then second, they can be adapted through various mechanisms like fine-tuning or scaffolding to perform specific tasks. Rather than learning from human-labeled examples for specific tasks, these models learn by finding patterns in huge amounts of unlabeled data.
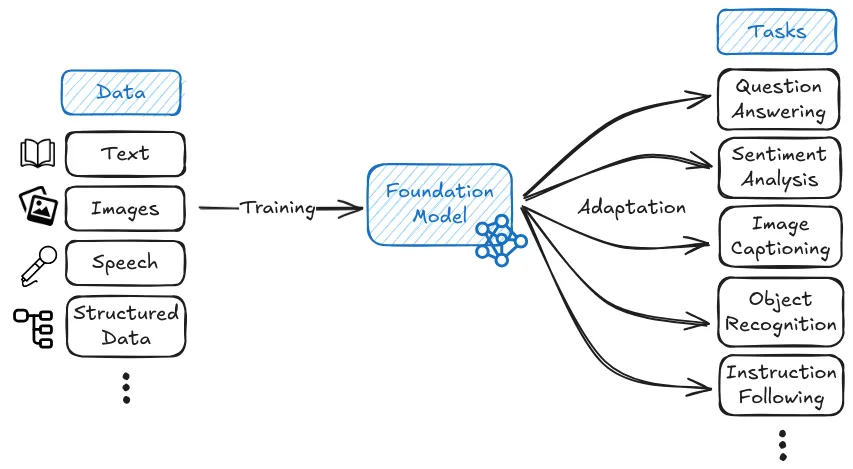
What is pre-training? Pre-training is the initial phase where the model learns general patterns and knowledge from massive datasets of millions or billions of examples. During this phase, the model isn't trained for any specific task - instead, it develops broad capabilities that can later be specialized. This generality is both powerful and concerning from a safety perspective. While it enables the model to adapt to many different tasks, it also means we can't easily predict or constrain what the model might learn to do (Hendrycks et al., 2022).
How does self-supervised learning enable pre-training? Self-supervised learning (SSL) is the key technical innovation that makes foundation models possible. This is how we actually implement the pre-training phase. Unlike traditional supervised learning, which requires human-labeled data, SSL leverages the inherent structure of the data itself to create training signals. For example, instead of manually labeling images, we might just hide part of a full image we already have and ask a model to predict what the rest should be. So it might predict the bottom half of an image given the top half, learning about which objects often appear together. As an example, it might learn that images with trees and grass at the top often have more grass, or maybe a path, at the bottom. It learns about objects and their context - trees and grass often appear in parks, dogs are often found in these environments, paths are usually horizontal, and so on. These learned representations can then be used for a wide variety of tasks that the model was not explicitly trained for, like identifying dogs in images, or recognizing parks - all without any human-provided labels! The same concept applies in language, a model might predict the next word in a sentence, such as "The cat sat on the … ," learning grammar, syntax, and context as long as we repeat this over huge amounts of text.
What is fine-tuning? After pre-training, foundation models can be adapted through two main approaches: fine-tuning and prompting. Fine-tuning involves additional training on a specific task or dataset to specialize the model's capabilities. For example, we might use Reinforcement Learning from Human Feedback (RLHF) to make language models better at following instructions or being more helpful. Prompting, on the other hand, involves providing the model with carefully crafted inputs that guide it toward desired behaviors without additional training.
Why does this training process matter for AI safety? The training process of foundation models creates several unique safety challenges. First, the self-supervised nature of pre-training means we have limited control over what the model learns - it might develop unintended capabilities or behaviors. Second, the adaptation process needs to reliably preserve any safety properties we've established during pre-training. Finally, the massive scale of training data and compute makes it difficult to thoroughly understand or audit what the model has learned. Many of the safety challenges we'll discuss throughout this book - from goal misgeneralization to scalable oversight - are deeply connected to how these models are trained and adapted.
Properties
Why do we need to understand the properties of foundation models? Besides just understanding the training process, we also need to understand the key defining characteristics or the abilities of these models. These properties often determine both the capabilities and potential risks of these systems. They help explain why foundation models pose unique safety challenges compared to traditional AI systems. Their ability to transfer knowledge, generalize across many different domains, and develop emergent capabilities means we can't rely on traditional safety approaches that assume narrow, predictable behavior.
What is transfer learning? Transfer learning is one of the most fundamental properties of foundation models - their ability to transfer knowledge learned during pre-training to new tasks and domains. Rather than starting from scratch for each task, we can leverage the general knowledge these models have already acquired (Bommasani et al., 2022). This property enables rapid adaptation and deployment, it also means that both capabilities and safety risks can transfer in unexpected ways. For example, a model might transfer not just useful knowledge but also harmful biases or undesired behaviors to new applications.
What are zero-shot and few-shot learning? The ability to perform new tasks with very few examples, or even no examples at all. For example, GPT-4 can solve novel reasoning problems just from a natural language description of the task (OpenAI, 2023). This emergent ability to generalize to new situations is powerful but concerning from a safety perspective. If models can adapt to novel situations in unexpected ways, it becomes harder to predict and control their behavior in deployment.
Generalization in foundation models works differently from traditional AI systems. Rather than just generalizing within a narrow domain, these models can generalize capabilities across domains in surprising ways. However, this generalization of capabilities often happens without a corresponding generalization of goals or constraints - a critical safety concern we'll explore in detail in our chapter on goal misgeneralization. For example, a model might generalize its ability to manipulate text in unexpected ways without maintaining the safety constraints we intended (Hendrycks et al., 2022).
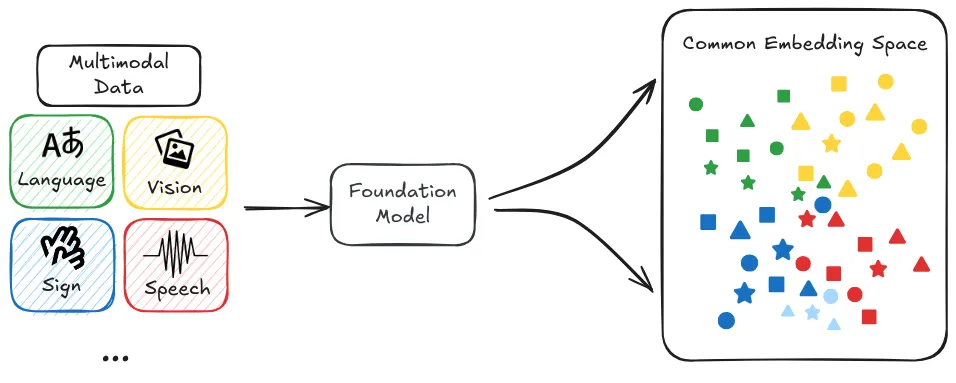
What is multi-modality? Models can work with multiple types of data (text, images, audio, video) simultaneously. This isn't just about handling different types of data. A better description is that they can make connections across modalities in sophisticated ways (Google, 2023). From a safety perspective, multi-modality introduces new challenges because it expands the ways models can interact with and influence the world. A safety failure in one modality might manifest through another in unexpected ways.
Multimodality will definitely be important. Speech in, speech out, images, eventually video. Clearly, people really want that. Customizability and personalization will also be very important.