
Compute is a powerful governance target because it meets all three criteria for effective governance targets:
- Measurability: Unlike data or algorithms, compute leaves clear physical footprints. Training frontier models requires massive data centers housing thousands of specialized chips (Pilz & Heim, 2023). We can track computational capacity through well-defined metrics like floating point operations (FLOPS), allowing us to identify potentially risky training runs before they begin (Heim & Koessler, 2024).
- Controllability: The supply chain for advanced AI chips has clear checkpoints. Only three companies dominate the current market: NVIDIA designs most AI training chips, TSMC manufactures the most advanced processors, and ASML produces the only machines capable of making cutting-edge chips. This concentration enables governance through export controls, licensing requirements, and supply chain monitoring (Grunewald, 2023; Sastry et al., 2024).
- Meaningfulness: As we discussed in the risks chapter, the most dangerous capabilities are likely to emerge from highly capable models, which require massive amounts of specialized computing infrastructure to train and run (Anderljung et al., 2023; Sastry et al., 2024). Compute requirements directly constrain what AI systems can be built - even with cutting-edge algorithms and vast datasets, organizations cannot train frontier models without sufficient computing power (Besiroglu et al., 2024). This makes compute a particularly meaningful point of intervention, as it allows us to shape AI development before potentially dangerous systems emerge rather than trying to control them after the fact (Heim et al., 2024).
The discussion in the next few subsections will focus on the elements of actually implementing compute governance. We explain how concentrated supply chains enable tracking and monitoring of compute, we also give a brief discussion of hardware based on-chip compute governance mechanisms, and finally discuss some limitations based around limitations to governance based on compute thresholds, and how distributed training and open source might challenge compute governance.
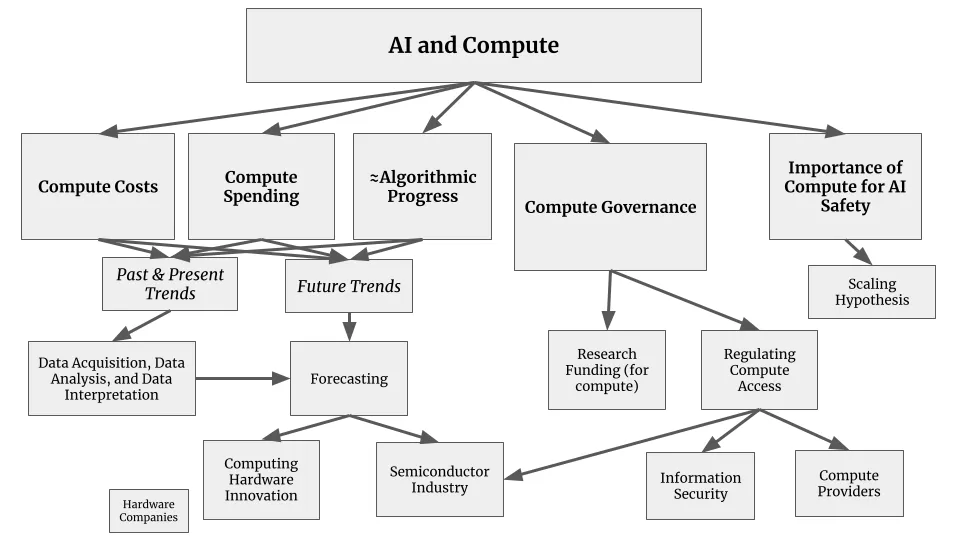
Tracking
AI-specialized chips emerge from a complex global process. It starts with mining and refining raw materials like silicon and rare earth elements. These materials become silicon wafers, which are transformed into chips through hundreds of precise manufacturing steps. The process requires specialized equipment (particularly, photolithography machines from ASML) along with various chemicals, gases, and tools from other suppliers (Grunewald, 2023).
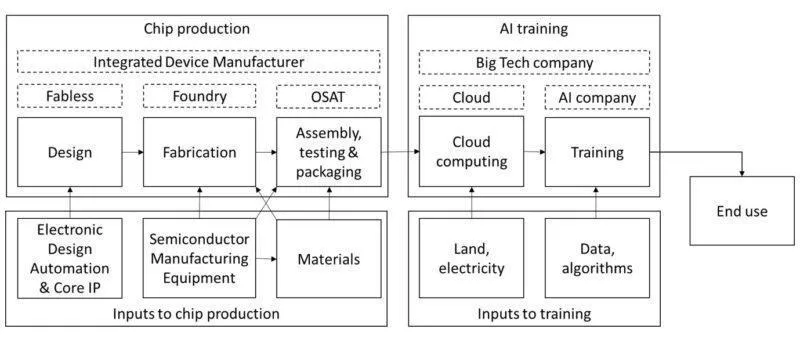
There are several chokepoints in semiconductor design and manufacturing. The supply chain is dominated by a handful of companies at critical steps. NVIDIA designs most AI-specialized chips, TSMC manufactures the most advanced chips, and ASML produces the machines needed by TSMC to manufacture the chips (Grunewald, 2023; Pilz et al., 2023). It is estimated that NVIDIA controls around 80 percent of the market for AI training GPUs (Jagielski, 2024). Similarly both TSMC, and ASML maintain strong leads in their respective domains (Pilz et al., 2023). Besides building the chips, the purchase and operation of them at the scale needed for frontier AI models requires massive upfront investment. In 2019, academia and governments were leading in AI supercomputers. Today, companies control over 80 percent of global AI computing capacity, while governments and academia have fallen below 20 percent (Pilz et al., 2025). Just three providers - Amazon, Microsoft, and Google - control about 65 percent of cloud computing services (Jagielski, 2024). A small number of AI companies like OpenAI, Anthropic, and DeepMind operate their own massive GPU clusters, but even these require specialized hardware subject to supply chain controls (Pilz & Heim, 2023).

Supply chain concentration creates natural intervention points. Authorities only need to work with a small number of key players to implement controls, as demonstrated by U.S. export restrictions on advanced chips (Heim et al., 2024). It is worth keeping in mind though that this heavy concentration is also concerning. We're seeing a growing "compute divide" - while major tech companies can spend hundreds of millions on AI training, academic researchers struggle to access even basic resources (Besiroglu et al., 2024). This impacts who can participate in AI development and reduces independent oversight of frontier models. It also raises concerns around potential power concentration.
Rather than trying to control all computing infrastructure, governance should focus specifically on specialized AI chips. These are distinct from general-purpose hardware in both capabilities and supply chains. By targeting only the most advanced AI-specific chips, we can address catastrophic risks while leaving the broader computing ecosystem largely untouched (Heim et al., 2024). For example, U.S. export controls specifically target high-end data center GPUs while excluding consumer hardware.
Monitoring
Training frontier AI models leaves multiple observable footprints which might allow us to detect concerning AI training runs. The most reliable is energy consumption - training runs that might produce dangerous systems require massive power usage, often hundreds of megawatts, creating distinctive patterns (Wasil et al., 2024; Shavit, 2023). Besides energy, other technical indicators include network traffic patterns characteristic of model training, hardware procurement and shipping records, cooling system requirements and thermal signatures, infrastructure buildout like power substation construction (Sastry et al., 2024; Shavit, 2023; Heim et al., 2024). These signals become particularly powerful when combined - sudden spikes in both energy usage and network traffic at a facility containing known AI hardware strongly suggest active model training.
Regulations have already begun using compute thresholds to trigger oversight mechanisms. The U.S. Executive Order on AI requires companies to notify the government about training runs exceeding operations - a threshold designed to capture the development of the most capable systems. The EU AI Act sets an even lower threshold of operations, requiring not just notification but also risk assessments and safety measures (Heim & Koessler, 2024). These thresholds help identify potentially risky development activities before they complete, enabling preventive rather than reactive governance.
Cloud compute providers can play an important role in compute governance. Most frontier AI development happens through cloud computing platforms rather than self-owned hardware. This creates natural control points for oversight, since most organizations developing advanced AI must work through these providers (Heim et al., 2024). Cloud providers' position between hardware and developers allows them to implement controls that would be difficult to enforce through hardware regulation alone. They maintain the physical infrastructure, track compute usage patterns and maintain development records. They can also monitor compliance with safety requirements, can implement access controls and respond to violations (Heim et al., 2024; Chan et al., 2024). One suggested approach is "know-your-customer" (KYC) requirements similar to financial services. Providers would verify the identity and intentions of clients requesting large-scale compute resources, maintain records of significant compute usage, and report suspicious patterns (Egan & Heim, 2023). This can be done while protecting privacy - basic workload characteristics can be monitored without accessing sensitive details like model architecture or training data (Shavit, 2023). Similar KYC laws can be applied to the supply chain on purchases of state of the art AI compute hardware.
On-Chip Controls
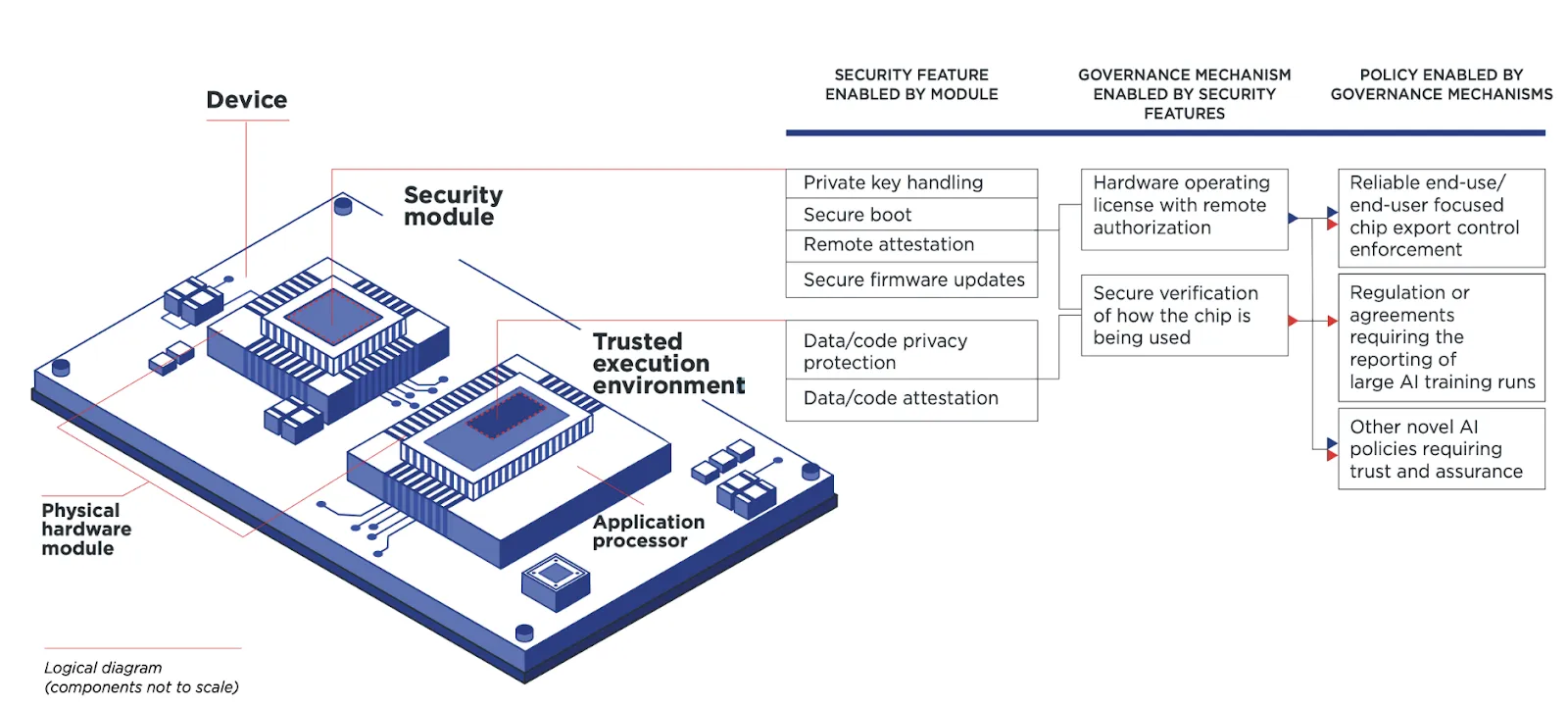
Beyond monitoring and detection, compute infrastructure can include active control mechanisms built directly into the processor hardware. Similar to how modern smartphones and computers include secure elements for privacy and security, AI chips can incorporate features that verify and control how they're used. These features could prevent unauthorized training runs or ensure chips are only used in approved facilities (Aarne et al., 2024). The verification happens at the hardware level, making it much harder to bypass than software controls. It is worth noting that on-chip controls are highly speculative.
On-chip controls could enable methods like usage limits, logging, and location verification. Several approaches show promise. Usage limits could cap the amount of compute used for certain types of AI workloads without special authorization. Secure logging systems could create tamper-resistant records of how chips are used. Location verification could ensure chips are only used in approved facilities (Brass & Aarne, 2024). Hardware could even include "safety interlocks" that automatically pause training if certain conditions aren't met. Ideas like this are also called on-chip governance (Aarne et al., 2024). We already see similar concepts in cybersecurity, with features like Intel's Software Guard Extensions, or trusted platform modules (TPM) (Intel, 2024) providing hardware-level security guarantees. While we're still far from equivalent safeguards for AI compute, early research shows promising directions (Shavit, 2023). Some chips already include basic monitoring capabilities that could be expanded for governance purposes (Petrie et al., 2024).
Limitations
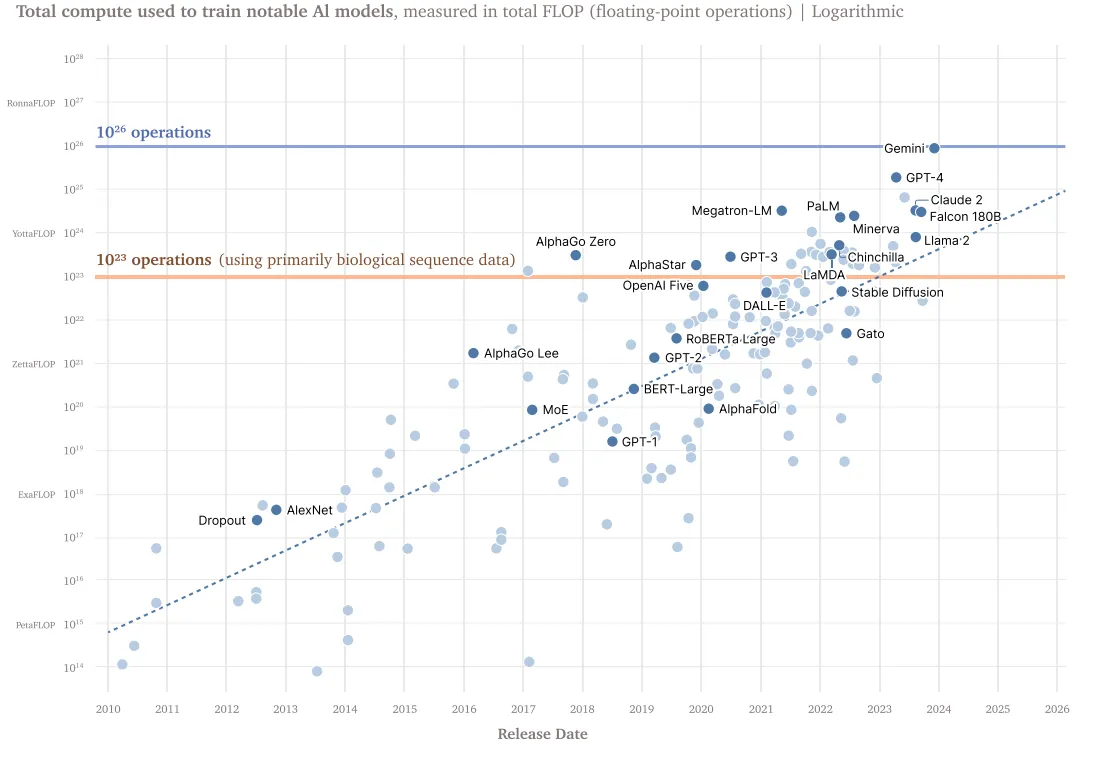
The trend over the last decade has involved more compute, but this will not last forever. We spoke at length about scaling laws in previous chapters. Research suggests scaling based returns to AI capabilities are still possible through 2030 (Sevilla et al., 2024). Algorithmic improvements also enhance efficiency, meaning the same compute achieves more capability over time. Smaller models could begin to show comparable capabilities and risks. For example, Falcon 180B is outperformed by far smaller models like Llama-3 8B. This makes static compute thresholds less reliable as capability indicators without regular updates (Hooker, 2024). Moreover, reasoning models (LRMs) and inference-time scaling (e.g. OpenAI o3, Claude 4, DeepSeek r1), and methods like model distillation can dramatically improve model capabilities without changing the amount of compute used to train a model. Current governance frameworks do not account for these post-training enhancements (Shavit, 2023).
Smaller more specialized models can still cause risks. Different domains have very different compute requirements. Highly specialized models trained on specific datasets might develop dangerous capabilities while using relatively modest compute. For example, models focused on biological or cybersecurity domains could pose serious risks even with compute usage below typical regulatory thresholds (Mouton et al., 2024; Heim & Koessler, 2024).
Compute governance can help manage AI risks, but overly restrictive controls can accelerate power concentration. Only a handful of organizations can afford the compute needed for frontier AI development. (Purtova et al., 2022; Pilz et al., 2023). Adding more barriers could worsen this disparity, concentrating power in a few large tech companies and reducing independent oversight (Besiroglu et al., 2024). Academic researchers already struggle to access the compute they need for meaningful AI research. As models get larger and more compute-intensive, this gap between industry and academia grows wider. (Besiroglu et al., 2024; Zhang et al., 2021) Large compute clusters have many legitimate uses beyond AI development, from scientific research to business applications. Overly broad restrictions could hinder beneficial innovation. Additionally, once models are trained, they can often be run for inference using much less compute than training required. This makes it challenging to control how existing models are used without imposing overly restrictive controls on general computing infrastructure (Sastry et al., 2024).
Distributed training and inference approaches could bypass compute governance controls. Currently, training frontier models requires concentrating massive compute resources in single locations due to communication requirements between chips. Decentralized training methods are being researched, but have not really caught up to centralized methods (Douillard et al., 2023; Jaghouar et al., 2024).[^footnote_decentralized_training] However, if we see fundamental advances in distributed training algorithms this could eventually allow training to be split across multiple smaller facilities. While this remains technically challenging and inefficient, it could make detection and control of dangerous training runs more difficult (Anderljung et al., 2023).
[^footnote_decentralized_training]: Example models trained using Decentralized methods include the INTELLECT-1 and INTELLECT-2 (Prime Intellect, 2025)
Compute monitoring and compute thresholds should primarily operate as an initial screening mechanism. These approaches should be used mainly to identify models warranting further scrutiny, rather than as the sole determinant of specific regulatory requirements. They are most effective when used to trigger oversight mechanisms such as notification requirements and risk assessments, whose results can then inform appropriate mitigation measures.
Technical governance measures need to coordinate with corporate, national and international initiatives. We focused on compute governance as our primary technical example, though coordination challenges apply equally to data governance, model governance, and other technical measures. Each approach faces the same fundamental limitation: technical measures alone cannot address systemic risks that emerge from competitive dynamics and global deployment. This is why technical measures must be embedded within corporate, national and international governance frameworks that align incentives with coordinated safety standards. Before we talk about those however, we need to explore broader concepts like decision making under uncertainty, game theoretic collective action problems and other systemic forces that shape the governance landscape. We will talk about this in the next section.